BOOKFIELD's Knowledge Base
【AI技術関連】WordCloudを用いた口コミデータのテキストマイニング
WordCloudは、文章中の頻出単語を選び、文字の大きさを変えながら並べる可視化手法で、その文章にどのような内容が含まれているかを簡潔に表現するものです。今回、口コミデータをWordCloudで表現してみたので紹介致します。使用した環境は以下の通りです。
Windows10(64Bit) + Python 3.6(Anaconda)
MeCabインストール
WordCloudで日本語を扱う場合、形態素解析エンジンが必要になります。今回、代表的な形態素解析エンジンであるMeCabを使用しましたが、pipインストールができないので、以下の手順で準備しました。
- MeCabのインストール
以下のサイトからMeCabをダウンロードしインストール
https://github.com/ikegami-yukino/mecab/releases/tag/v0.996 - 環境変数へのpath追加(Cドライブにインストールした場合)
C:\Program Files\MeCab\bin - MeCabの動作確認
・コンソールで「mecab」と入力
・「形態素解析」など適当な文字列を入力しエラーが出なければOK
※この時文字化が発生することがあるが気にしなくてよい - mecab-pythonの導入(Anacondaプロンプトで実行)
・pip install ipykernel
・pip install mecab-python-windows - 「libmecab.dll」ファイル確認
・Anacondaがインストールされているフォルダの「Lib/site-packages」に「libmecab.dll」があればOK
※無かった場合にはMeCabをインストールしたフォルダの「/bin」から複写 - 動作確認
・Pythonを起動し「import MeCab」と入力してエラーにならなけれOK
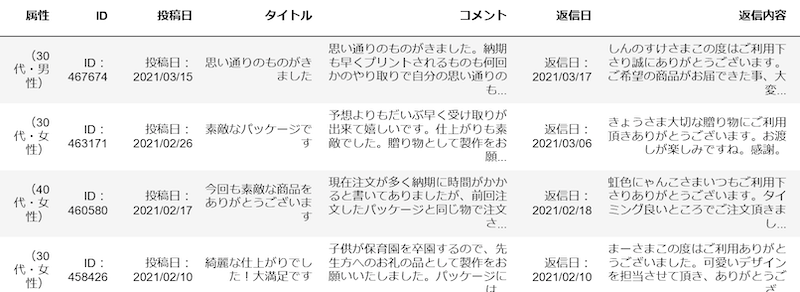
口コミデータ
今回の口コミデータは以下のデータ形式(csv)のものを使用しました。WordCloudで表現したいのは、このうちの「コメント」列になります(データ数は100)。
コーディング
Pythonでのコーディングは以下の通りとなります。
import MeCab
import pandas as pd
from wordcloud import WordCloud
# コメント列の読み込み
df = pd.read_csv("./口コミ.csv", encoding = "shift-jis")
comment = df.コメント
# リスト形式のデータを文字列(String型)に変換
str_comment = "".join(comment)
#ストップワードの設定(実際にはもっと多くのワードを設定しています)
stop_words = [ u'また機会があればお願いしたいと思います', u'ありがとうございました',¥
u'また宜しくお願いします', u'大変満足しています']
# WordlCloud 実行
FONT_FILE = "C:¥Windows¥Fonts¥meiryo.ttc"
wc = WordCloud(width=1200, height=1000, font_path=FONT_FILE, background_color="white", colormap="gist_heat",¥
stopwords=set(stop_words), max_words=50)
wc.generate(str_comment)
wc.to_file('comment_wc.png')フォントのファイル名でチト悩みましたが、以下のページに書かれたファイル名を使うと上手くいきました。
https://helpx.adobe.com/jp/x-productkb/global/cq08041028.html
作成したWordCloud
今回作成したWordCloudの出力結果です。この事業者の対応の良さやサービスの特徴がよく表れていると思います。ゼロって何?(笑)

MeCabのインストールが少々手間ですが、比較的容易にテキストマイニングの一端を垣間見ることが出来ますので、お試し下さい。